E Reputation Systems with Limited Correlations
Our treatment discusses a wide yet restricted class of reputation systems, namely
correlation-free reputation
systems. Recall that this means that the reputation of a reputation-party 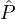 i (i.e.,
i (i.e.,  i’s probability of becoming
corrupted) does not depend on the reputation of other parties
i’s probability of becoming
corrupted) does not depend on the reputation of other parties 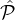 j. The reason for such an assumption is that if one
allows for arbitrary correlations in these probabilities, then it is easy to find reputation systems in which every
party
has probability of not becoming corrupted strictly less than 1∕2, yet for any (randomized) sampler the selected
corrupted parties will be in the majority with overwhelming probability. An example of such a situation was given
in [47].
j. The reason for such an assumption is that if one
allows for arbitrary correlations in these probabilities, then it is easy to find reputation systems in which every
party
has probability of not becoming corrupted strictly less than 1∕2, yet for any (randomized) sampler the selected
corrupted parties will be in the majority with overwhelming probability. An example of such a situation was given
in [47].
Despite the above strong impossibility result, our mechanism can be applied, either directly or with modifications, to deal with several classes of dependent reputations. This differentiates our definition and use of reputation systems from approaches like [25], which are applied to special distributions. In the following, we discuss some of the distribution classes we can tolerate; a more complete investigation is left as an open research direction.
n-wise independent reputation systems. A wide class of correlated reputation systems which can still be used for our goals is one in which the random variables corresponding to the honesty indicator bits are of n-wise independent for a logarithmic (in the size of the reputation set) n. In fact, our original algorithm will work for such a distribution. This idea of n-wise independence can also be extended to capture additional distributions along the lines of [13, Theorem 4.3].
Reputation-systems which are approximately correlation-free. The following definition says that a reputation system is δ-correlation-free if and only if it is a δ-close to a correlation-free reputation system.
Definition 4 (δ-correlation-free reputation system). Let Rep be a (potentially non-correlation-free)
reputation system for a reputation set 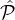 . For each
. For each 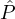 i ∈
i ∈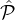 , let γi denote the probability, according to Rep,
that
, let γi denote the probability, according to Rep,
that 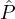 i gets corrupted. Let RepIND denote the correlation-free reputation system derived from
i gets corrupted. Let RepIND denote the correlation-free reputation system derived from 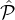 , where
each party gets corrupted with probability γi independent of other corruptions. Then we say that Rep is
δ-correlation-free reputation system if and only if the statistical distance of Rep and RepIND is at most δ.
, where
each party gets corrupted with probability γi independent of other corruptions. Then we say that Rep is
δ-correlation-free reputation system if and only if the statistical distance of Rep and RepIND is at most δ.
It is straightforward to verify that is δ is very small (negligible in |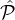 |) and RepIND is feasible, then our sampling
algorithm discussed above will directly select sets with honest majority. Furthermore, assuming sufficiently
many parties with high reputation in RepIND, we can modify our sampling to retain the selection of
honest majority even when δ is a small constant. The idea, which will be detailed in the research
paper accompanying this white paper, is to move the boundaries of the high-reputation buckets so that
any errors that occur by δ-bounded correlations are leveraged by the higher probability of honest
parties.
|) and RepIND is feasible, then our sampling
algorithm discussed above will directly select sets with honest majority. Furthermore, assuming sufficiently
many parties with high reputation in RepIND, we can modify our sampling to retain the selection of
honest majority even when δ is a small constant. The idea, which will be detailed in the research
paper accompanying this white paper, is to move the boundaries of the high-reputation buckets so that
any errors that occur by δ-bounded correlations are leveraged by the higher probability of honest
parties.
We note in passing, that the above allows us to also capture situations in which the reputation system is inaccurate but only by a bounded amount (e.g., the corruption probabilities that it predicts are off by up to a δ factor from the actual probabilities that the parties get corrupted.) Thus in addition to our fallback security property—which will ensure that as long as the majority of the stake in the system is in honest hands, the blockchain will not fork even with inaccurate reputations—if the number of parties with high (estimated) reputation permits it, then we can design our blockchain so that it is resilient to small inaccuracies in the reputation.

